Nvidia představila svou budoucnost. Co od Ampere čekat?
Nová architektura grafických jader společnosti Nvidia se zpočátku objeví ve variantách pro nasazení v serverech a datových centrech (akcelerátor Nvidia A100 se již vyrábí), ale později na ní budou stavět také spotřebitelské produkty jako herní série GeForce.
Nvidia Ampere staví na 7nm výrobním procesu, dodavatelem čipů je společnost TSCM, a oproti předchozím architekturám Turing a Volta přináší řadu nových technologií a vylepšení, které přijdou vhod nejen při náročných operacích, jako jsou výpočty související s umělou inteligencí či neuronovými sítěmi. I když je nutné hned v úvodu dodat, že je to právě oblast HPC, která bude z nové architektury těžit nejvíce.
Později se však, navzdory nejrůznějším spekulacím, které představení nové architektury doprovázely, architektura Ampere objeví i ve spotřebitelských řadách grafických čipů (GeForce a Quadro), k čemuž však v tuto chvílí nejsou k dispozici žádné další informace.
Klíčové inovace v Nvidia Ampere
Třetí generace Tensor Core
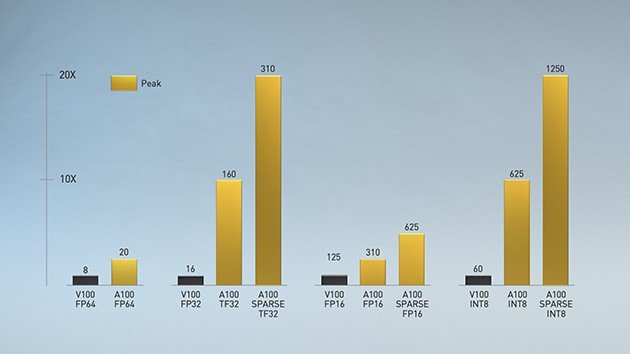 První generace technologie Tensor Core se objevila již v architektuře Volta a přinesla dramatické zrychlení AI výpočtů, které za pomoci masivního výkonu dokázala v některých případech řádově urychlit z týdnů na hodiny. Pro další urychlení a zjednodušení výpočtů Nvidia zavádí nové výpočetní modely Tensor Float (TF32) a Floating Point 64 (FP64). Např. nový TF32 má pracovat stejně jako FP32, ale pro AI výpočty má přinést až 20× zrychlení bez nutnosti provádět jakékoli změny v kódu. Další až 2× urychlení výpočtů má pak přinést i metoda Automatic Mixed Precision, jehož zprovoznění má být také velmi jednoduché, tentokrát se však již bez drobné úpravy kódu neobejde.
První generace technologie Tensor Core se objevila již v architektuře Volta a přinesla dramatické zrychlení AI výpočtů, které za pomoci masivního výkonu dokázala v některých případech řádově urychlit z týdnů na hodiny. Pro další urychlení a zjednodušení výpočtů Nvidia zavádí nové výpočetní modely Tensor Float (TF32) a Floating Point 64 (FP64). Např. nový TF32 má pracovat stejně jako FP32, ale pro AI výpočty má přinést až 20× zrychlení bez nutnosti provádět jakékoli změny v kódu. Další až 2× urychlení výpočtů má pak přinést i metoda Automatic Mixed Precision, jehož zprovoznění má být také velmi jednoduché, tentokrát se však již bez drobné úpravy kódu neobejde.
Třetí generace rozhraní NVLink
Škálování aplikací napříč více GPU vyžaduje extrémně rychlé datové přenosy. Třetí generace rozhraní NVLink dokáže až zdvojnásobit rychlost GPU-to-GPU komunikace až na 600 GB/s, což je asi 10× více než u PCIe čtvrté generace. Plné rychlosti vzájemné GPU komunikace lze využít v kombinaci s nejnovější generací Nvidia NVSwitch.
 Multi-Instance GPU (MIG)
Multi-Instance GPU (MIG)
V případě opravdu výkonných řešení je někdy problém jednou jedinou aplikací či úlohou využít veškerý dostupný výkon. Díky technologii MIG lze dostupný výkon „rozporcovat“ až do sedmi samostatných a na úrovni hardwaru izolovaných GPU s vlastními jádry, pamětí i cache. Uživatelé tak mohou na jednom fyzickém řešení současně provozovat více menších i větších aplikací s garantovanou dostupností i kvalitou. Stejně tak tato technologie představuje přínos i pro IT administrátory, kteří budou schopni lépe a přesněji distribuovat výpočetní výkon každému uživateli a každé aplikaci (využitelné v bare-metal i virtualizovaném prostředí).
Rychlejší a chytřejší paměti
Aby byly výpočetní možnosti nové architektury Ampere využity skutečně na maximum, používají se paměti s propustností až 1,6 terabytů za sekundu. Nárůst oproti předchozí generaci tak činí až 67 %.
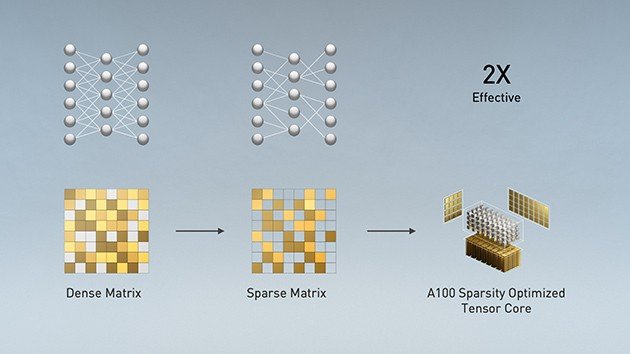 Structural Sparsity
Structural Sparsity
Moderní AI sítě jsou velké a stále se zvětšují. Mají miliony nebo miliardy parametrů. Ne všechny z těchto parametrů jsou však nezbytné pro přesné předpovědi a závěry, a lze je proto převést na nuly. Modely se tak stávají více „řídké“ a výpočty se tak mohou bez jakéhokoli ovlivnění výsledků urychlit. Více informací se o této metodě dočtete zde.
Nvidia GA100
První čip postavený na nové architektuře nese jméno Nvidia GA100 a výrobce slibuje, že oproti předchůdcům je až 20× výkonnější. GPU je postavené na 7nm výrobním procesu, obsahuje přes 54 miliard tranzistorů a samozřejmě využívá všechny výše představené novinky. Ve srovnání s architekturou Volta je prý až 6× výkonnější při tréninku AI výpočtů a až 7× rychlejší při doručování výsledků.

Plocha GPU je 826 mm2, k dispozici je 8 192 Cuda jader a 48 GB vysokorychlostní paměti HBM2E (připojených skrze 6 144bitovou sběrnici). Velikost Level 2 cache paměti 48 MB s kompresí (která při vhodných operacích zvyšuje výkon). Cuda jádra (shadery) jsou členěny do osmi GPC bloků, které se dále dělí na osm podbloků (TPC). Každý podblok pak obsahuje dva bloky SM se 64 shadery a čtyřmi tensor jádry.
Nvidia A100
Prvním řešením, které čipy GA100 využívá, je akcelerátor Nvidia A100. Ve srovnání se specifikacemi, které uvádíme výše, však u čipu GA100 došlo k omezení některých vlastností. Pravděpodobně tomu tak je z ekonomických důvodů, protože výroba ještě nemusí být 100% odladěná, a Nvidia takto bude moci efektivněji využít i z výroby částečně defektní produkci (vadné části čipů se vypínají).

Oproti specifikaci čipu GA100 je v případě karty A100 k dispozici pouze sedm GPC (a tedy jen 6 912 Cuda jader a 432 tensor jader). Zredukovaná je také paměť – na 40 GB HBM2E paměti + 40 MB L2 cache. Samozřejmostí je podpora PCI Express Gen 4. Spotřeba se pak šplhá až na 400 W. Karta bude minimálně zpočátku dostupná pouze v provedení SXM4 pro osazení přímo na desku.
Nvidia DGX A100
Rovněž nově představený výpočetní serverový nod Nvidia DGX A100 přináší výkon pět petaflops dosažený složením výkonu osmi GPU Nvidia A100 propojených nejnovější revizí rozhraní NVLink. Díky technologii Multi-Instance GPU, o které jsme již hovořili, toto řešení umožňuje současně provozovat až 56 různých aplikací. Další výbavu tvoří dva procesory AMD (Rome), 1TB operační paměť DDDR4, 15TB NVMe SSD a devět síťových karet Mellanox s propustností 200 Gb/s.

Pro lepší ilustraci výkonu Nvidia uvádí, že pět jednotek DGX A100 dokáže při spotřebě 28 kilowattů dokáže nahradit 50 jednotek DGX-1 a 600 CPU se spotřebou 630 kilowattů. Cena novinky je 199 000 USD.
DGX A100 SuperPOD
Pro datová centra a další pracoviště vyžadující skutečně maximální možný výkon, bude k dispozici i řešení DGX A100 SuperPOD složené ze 140 systémů DGX A100. Celkem bude tedy čítat 1 120 akcelerátorů A100 doplněných o 170 200Gb síťových karet Mellanox, 4PB extrémně rychlého flash úložiště nebo 15 km optických kabelů.
Optimalizovaný software
Vedle představení nové architektury Nvidia současně pro její potřeby upravila a vylepšila software tak, aby mohli vývojáři využít výkon i nové možnosti naplno. Světlo světa tak spatřilo přes 50 nových verzí CUDA-X knihoven optimalizovaných pro práci s AI, ML, simulacemi apod. Inovovány byly i další nástroje včetně Nvidia Jarvis, Nvidia Merlin či Nvidia HPC SDK.
Pro zájemce, kteří by si chtěli novinky prostudovat detailně, Nvidia připravila např. tuto stránku.








