Jaké novinky přinesou serverové grafiky Nvidia Hopper?
Společnost Nvidia na své březnové globální vývojářské konferenci Nvidia GTC představila detaily ohledně architektury Hopper i grafických čipů GH100, které z ní přímo vycházejí. Nová grafická platforma míří do datových center, serverů a dalších výkonných HPC řešení, kam by měla přinést (nejenom) zásadní zrychlení u výpočtů založených na umělé inteligenci a strojovém učením.
- 29. 3. 2022
- 8 min

Umělá inteligence a strojové učení patří mezi klíčové oblasti, na které se novinky v Nvidia Hopper primárně soustředí. V souvislosti s využitím vlastností nové architektury společnost Nvidia hojně zmiňuje nasazení do oblastí, jako jsou nejrůznější hlasové a konverzační systémy, nástroje uživatelské podpory a servisu nebo platformy schopné interaktivně pomáhat uživatelům v reálném čase nebo jim do(po)ručovat informace, které se jim mohou v daném okamžiku hodit (např. během nákupního procesu nebo konfigurace zboží na míru). Velmi silná by měla nová platforma být také v případě vyhodnocování a zpracovávání nasbíraných surových dat a jejich předávání AI modelům, které se na jejich prostřednictvím mohou učit a zdokonalovat.
Na základech nové architektury staví karta (technicky vzato spíše akcelerátor) Nvidia H100, jejíž produkce probíhá (u GPU vůbec poprvé) na 4nm výrobním procesu (konkrétně pak u firmy TSMC – takto to alespoň prezentuje samotná Nvidia, podle některých informací však půjde spíš o vylepšený 5nm produkční proces). Čip se skládá až z 80 miliard tranzistorů a slibuje obrovský mezigenerační posun – ve srovnání se starším modelem A100 přináší podle Nvidie v některých typech operací až 40× vyšší výkon. Jednou z oblastí, kde by měl být nárůst výkonu nejpatrnější, je tzv. dynamické programování, jehož algoritmy se využívají při řešení komplexních problémů v oblastech jako zdravotnictví, robotika, kvantové výpočty nebo datová věda (a ke kterému se ještě krátce dostaneme později).
Změn je skutečně mnoho
Ve srovnání s předchůdcem narazíme na změny a inovace na mnoha místech – Nvidia zapracovala na vylepšení výkonu, zvýšení paměťové propustnosti, bezpečnosti nebo např. I/O.
Základem nové grafické karty jsou čipy GH100. V maximální možné výbavě akcelerátor zahrnuje osm GPC bloků (Global Processing Cluster) a 72 TPC bloků (Texture Processor Cluster). Každý GPC blok je tedy tvořen devíti TPC segmenty s tím, že každý TPC segment je následně dvořen dvěma SM bloky, z nichž každý obsahuje 144 cuda jader (neboli shaderů). Celkově tak hovoříme o 18 432 FP32 cuda jádrech. Každý SM blok navíc ještě obsahuje i čtyři Tensor jádra – v maximální konfiguraci je tedy těchto jader na čipu 576.
Evolucí prošla také Tensor jádra. Nově sem byl totiž doplněn tzv. Transformer Engine určený primárně pro urychlení tréninku AI modelů. Tensor jádra architektury Hopper mají schopnost kombinovat výpočty typu FP8 a FP16, čímž dokáží výrazně urychlit celou řadu operací. Až třikrát rychlejší (za sekundu – ve FLOPS) je oproti předchozí generaci také zpracování operací s plovoucí desetinou čárkou u výpočtů typu TF32, FP64, FP16 a INT8.
Nvidia samozřejmě opět vsadila na paměti HBM, v tomto případě konkrétně na typ HBM3, nebo alternativně HBM2e. Paměťový řadič využívá 12 512bitovou sběrnici. Propustnost tedy vzrostla až na 3TB/s. L2 cache paměť má kapacitu 60 MB. Velikost čipu je 814 mm2.
Moderní komunikační rozhraní
Součástí nové grafické architektury je také nová generace komunikačního rozhraní NVLink 4. Toto rozhraní, specializované na komunikaci grafických čipů (a brzy také procesorů) se specializuje na co nejvyšší datovou propustnost a co nejlepší možnosti vzájemné komunikace velkého množství grafických karet (čipů).
V kombinaci s novým externím síťovým zařízením NVLink Switch nová technologie nabízí obousměrnou komunikaci rychlostí až 900 GB/s, což je 7× více než u PCIe Gen5. Systém NVLink Switch podporuje clustery složené až z 256 kusů karet H100 a nabízí 9× vyšší propustnost než rozhraní InfiniBand HDR u řady Ampere. Oproti A100 tedy hovoříme až o dvounásobném zvýšení I/O výkonu.
Navíc pak NVLink nyní nabízí i tzv. „in-network“ výpočty, nazývané jako „SHARP“, které byly již dříve dostupné pro rozhraní Infiniband. Díky tomu lze dosáhnout na výpočetní výkon až jeden exaFLOP (u výpočtů typu FP8 sparsity AI) a šířku pásma (All2All) až 57,6 TB/s.

Doplněna byla také podpora rozhraní PCIe 5.0, což je důležité primárně kvůli komunikaci mezi grafickými a procesorovými částmi zařízení. Nvidia tak zdvojnásobila šířku pásma mezi CPU a GPU, což jí umožňuje udržovat H100 mnohem lépe zásobenou potřebnými daty. Na druhou stranu je jasné, že aby vše fungovalo na maximum, bude nutné na hostitelském zařízení nasadit také patřičně vybavené procesy, které však AMD ani Intel aktuálně nedokážou poskytnout. Na druhou stranu se dá předpokládat, že situace se do doby, než se novinky během třetí čtvrtletí dostanou na trh, změní v k lepšímu.
Přítomnost druhé generace protokolu MIG (Multi-Instance GPU) pak umožňuje grafické čipy rozdělit na menší, nezávislé skupiny s vlastní pamětí, cache i výpočetními (CPU) jádry. Architektura Hopper zachází ještě dál a mimo jiné přináší opět o něco lepší podporu multitenantních a multi-uživatelských konfigurací ve virtuálních prostředích, kterým umožňuje nárokovat si až 7 GPU instancí navzájem bezpečně izolovaných na úrovni hardwaru (hypervizoru). Přidána byla mimo jiné také podpora dedikovaných dekodérů videa pro každou z instancí pro bezpečnější a výkonnější analytiku obrazu na sdílené infrastruktuře.
Dostupná ve dvou provedeních
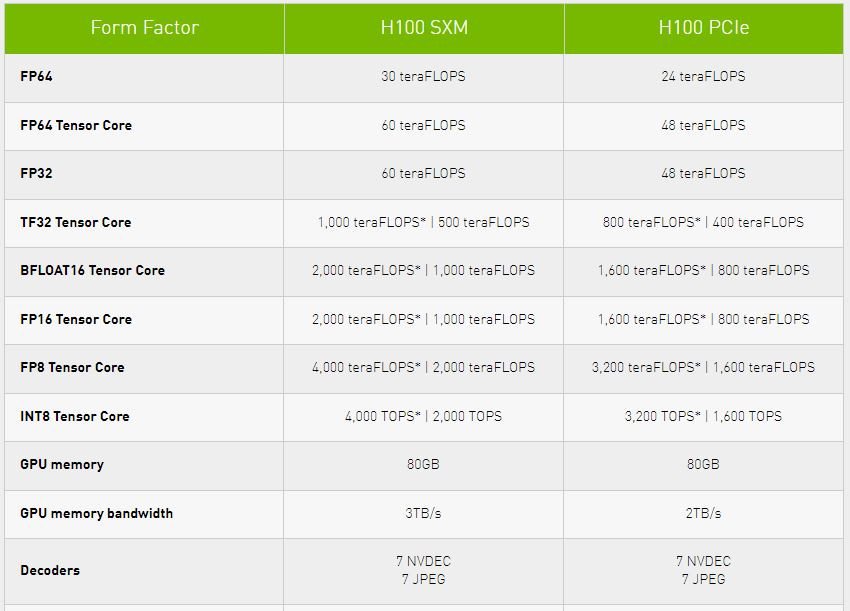
Akcelerátor Nvidia H100 bude dostupný ve dvou formátech – jako SXM modul pro vysoce výkonné servery a PCIe karta pro běžnější řešení. Zejména nároky na napájení oproti předchozí generaci výrazně stouply – SXM verze si řekne o 700 W (TDP) a PCIe varianta si vyžádá 350 W. (V tomto případě bude zároveň zajímavé sledovat, jak se Nvidia vypořádá s chlazením, protože u novinky je překročen doporučený limit pro chlazení PCIe karet běžně stanovený na 300 W.)
Vlastnosti karet se budou v závislosti na provedení samozřejmě lišit ve více ohledech. Varianta SXM disponuje 8 GPC, 66 TPC a 132 SM bloky. Ve výsledku pak půjde o 16 896 cuda jader. Tensor jader bude k dispozici 528. K dispozici bude rovněž 80 GB paměti HBM3. PCIe verze karty přinese 7 nebo 8 GPC, 57 TPC a 114 SM bloků. V tomto případě tedy 14 592 cuda jader doplní 456 jader typu Tensor. K dispozici bude rovněž 80 GB paměti, zde však v provedení HBM2e.
„Confidential Computing“ pro vyšší bezpečnost
Vedle zvyšování výkonu se Nvidia u nové platformy Hopper zaměřila také na bezpečnost, která je zejména kvůli stále častějšímu využívání grafických akcelerátorů v cloudových prostředí a jejich sdílení ve virtualizovaných řešeních stále palčivější problematikou.
Odpovědí na možné obavy je vytvoření bezpečného a důvěryhodného prostředí na hardwarové úrovni. Jednou z novinek je např. možnost vytvoření tzv. důvěryhodného virtualizovaného zařízení, kde jsou veškerá data zabezpečená a vstupují (i odcházejí) zašifrovaná. O bezpečnost se technicky starají prvky na softwarové i hardwarové úrovni, ale vše včetně šifrování dat by mělo být natolik rychlé, že by nemělo kvůli tomu docházet k žádnému praktickému zpomalení či snížení výkonu.
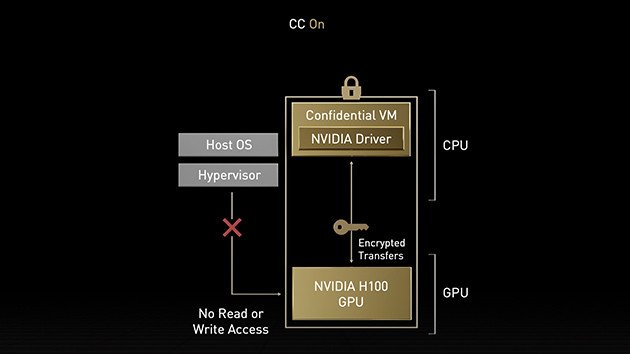
Toto tzv. důvěryhodné prostředí je navrženo tak, aby obstálo proti všem myslitelným způsobům narušení. Obsah paměti v GPU samotném je dle Nvidie zabezpečen tzv. hardwarovým firewallem, který by měl zabránit proniknutí vnějším procesům. Stejná metoda chrání i „in-flight“ provozní data ve virtualizovaném zařízení. Prostředí je navíc zabezpečené také proti nevyžádaným přístupům ze strany OS či hypervizoru. Data by tedy nemělo být možné ze zařízení dostat žádným způsobem ani při získání fyzického přístupu k zařízení.
Je tedy zřejmé, že Nvidia v tomto ohledu dělá všechno, co je v jejich silách, aby přesvědčila své zákazníky o tom, že se moderních řešení a přístupů nemusejí obávat ani v souvislosti se zpracováním jakkoli citlivých dat, a to ani ve (sdíleném) cloudovém či jinak specifickém (např. edge) prostředí.
Instrukce pro dynamické programování
Dynamické programování (DPX) je způsob fungování algoritmů, který řeší komplexní problémy jejich rozložením do menších částí. Výsledky jednotlivých výpočtů jsou následně ukládány, aby je nebylo nutné znovu počítat v budoucnu, což redukuje čas a složitost takových operací. Jde přitom o velmi praktickou techniku využívanou velmi často – příkladem může být plánování tras nákladních lodí nebo sekvenování DNA v souvislosti se skládáním proteinů. Díky tomu, že Nvidia Hopper DPX instrukce nativně podporuje, umožňuje související výpočty urychlit až 40× ve srovnání s jejich zpracováním pomocí CPU a až 7× oproti vyhodnocování na akcelerátorech vycházejících z předchozí generace Nvidia Ampere.
Dostupnost letos na podzim
Nvidia zároveň potvrdila, že pro H100 zaktualizuje celý svůj ekosystém základních desek HGX pro různá prostředí a různé dodavatele.
Stejně jako systémy DGX POD a DGX SuperPOD, které budou akcelerátory Nvidia H100 využívat, se i samotné karty (např. pro OEM vendory) dostanou do prodeje ve třetím čtvrtletí roku 2022.








